
DeFi(分散型金融)を始め、ブロックチェーンを活用した技術では「分散化・分散型」が重要なキーワードになっています。
分散型IDもその一つです。
Web2と呼ばれる中央集権的なインターネットの世界では、わたしたち個人は自らの個人情報やデータを真の意味で保有・管理することができていません。
分散型IDはこの状況を覆し、個人が自分の情報・データ管理に対する主権を取り戻すことができる技術です。
この記事では分散型IDの概念および基盤となる技術、そしてなぜ今、分散型IDが重要とされているのかを解説します。
この記事の構成
分散型IDとは?
分散型IDは特定の企業や組織に依存することなく、自分自身に関する情報を証明する仕組みです。あるいは、管理主体に依存せず個人が自ら保有・管理できる個人情報そのものでもあります。
分散型IDに類似した概念でよく論じられるものとして、DID(Decentralized Identifier)があります。
そこでまずは、分散型IDとDIDの違いを明らかにします。その上で、分散型IDが注目される原因となったWeb2のインターネットにおける情報管理の問題点について解説します。
分散型IDとDIDの違い

分散型IDとDIDは混同して用いられることがありますが、厳密には異なります。
DID(Decentralized Identifier)は「分散型識別子」と呼ばれる文字列そのものを意味しています。
識別子とは、数多くの物体や情報の中から一意的に区別するための文字列です。
具体的にイメージするために、日常生活の事例で解説します。
識別子に該当するものとしては、たとえば以下が挙げられます。
- マイナンバー
- 健康保険証の記号番号
- 社員番号
- 運転免許証の番号
いずれの場合も、同一の文字列は存在しません。一人の個人に対して一つの文字列が対応することで、その個人を一意的に特定できます。
DIDはこれらと同じく、それ自体はただの文字列であり、DIDだけでその個人に関する何らかの情報が得られるわけではありません。
これに対して分散型IDは、DIDおよび後述するSelf Sovereign Identity(SSI)、Verifiable Credentials(VCs)といった概念によって成立する個人情報そのもの、あるいはその情報を管理する仕組みを指します。
上記の運転免許証を例にするならば、免許証に記載されている12桁の個別の番号がDIDにあたります。
一方、この免許証の持ち主をAさんとした場合、免許証には「普通車のみ運転可能」「運転時はメガネを着用すること」など、Aさんという特定の個人に紐付けられる情報がすべて記載されています。分散型IDも同様に、特定の個人に紐づく情報の集合体であると言えます。
Web2における個人情報管理の問題点

Web2と呼ばれる現在のインターネットは、中央集権的な構造をしていると言われます。
中央集権的とは、個人情報の保有・管理が国家やGAFAを始めとする企業等の管理者にすべて委ねられているという意味です。
そして現在、このようなデータ管理のあり方が問題視されています。その理由を、具体例を取り上げて解説します。
膨大な数のアカウントを保有・管理する必要がある
免許証やパスポートは、それ一つで自分が何者であるかを示してくれる物理的なIDであると言えます。
ところがインターネットの世界では、自分が何者であるかを客観的に示してくれるデジタルなIDがありません。
したがってわたしたちは、インターネット上のサービスを利用するには自分が何者であるかを都度入力し、自分に紐づくアカウントを作成しなければなりません。
Amazon、Google、Facebookなどの巨大テック企業のサービス利用時はもちろん、銀行や証券会社の口座開設時、音楽のサブスクリプションサービス利用時に至るまで、あらゆる場面で毎回自分の情報を入力して自分が何者であるかを相手に伝え、アカウントを作成し、個々に管理する必要があります。
管理するアカウントが膨大に増えた結果、めったに使わないサービスのログインパスワードを忘れてしまったという経験は、誰もが一度はあるはずです。
このようにWeb2のインターネットにおける情報管理の仕組みでは、個人が膨大な数のアカウントを都度作成して管理しなければならない点が問題であるとされています。
管理者側の判断次第でサービスが利用できなくなる可能性がある
TwitterやYouTubeのアカウントがいきなり利用停止にされた経験がある人もいるかもしれません。
わたしたちは、一度アカウントを作成したサービスは自由に使えるように考えがちですが、実はこの認識は間違いです。
管理者側の恣意的な判断で、アカウントはいつでも利用停止(BAN)にされる可能性があります。
元アメリカ大統領のトランプ氏がTwitterのアカウントを永久凍結された話は有名です。
TwitterなどのSNSで発信したコンテンツはあたかも自分個人の所有物に見えますが、実はわたしたちはそのコンテンツを所有しておらず、すべて運営企業の管理下にあります。
企業の判断でサービスの利用停止処分を受けた瞬間、個人の手元には一切データが残らず、その後サービスを利用することもできなくなってしまいます。
個人情報の漏洩リスクがある
企業も情報管理に力を入れているものの、ミスによる個人情報の漏洩や、ハッキング被害等で流出する可能性は常にあります。
一度企業側に渡してしまった情報は個人の手でコントロールすることは出来ません。
個人情報が漏洩するかもしれないリスクをすべて企業側に依存してしまっている点も、Web2の大きな課題だと言えます。
分散型IDの仕組み

引用元:LasTrust
Web2の中央集権的なデータ管理と、それによる弊害を解決できる可能性がある技術が分散型IDです。
分散型IDは以下の3つの概念によって成立しています。
- Decentralized Identifier(分散型識別子:DID)
- Verifiable Credentials(検証可能な個人情報:VCs)
- Self Sovereign Identity(自己主権型アイデンティティ:SSI)
Decentralized Identifier(分散型識別子)
Decentralized Identifier(DID)は情報にアクセスするための文字列(識別子)です。
DIDには、インターネットを閲覧する際のURLと同様にリンクがあり、アクセスすることでDIDにリンクされた情報を閲覧できます。DIDは以下のような文字列で表現されます。
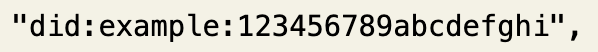
引用元:Decentralized Identifiers (DIDs) v1.0
そして、DIDにリンクした情報は「DID Document」と呼ばれ、以下のような文字列で表現されます。
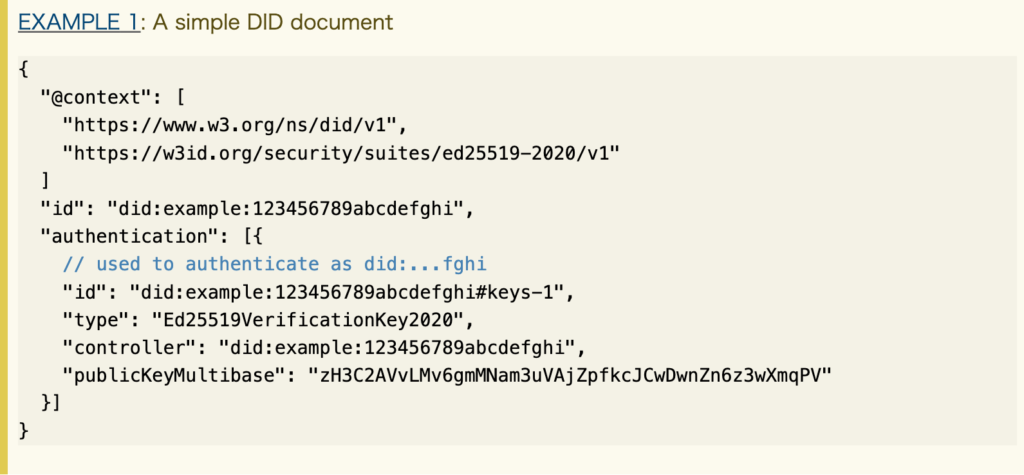
引用元:Decentralized Identifiers (DIDs) v1.0
このDID Documentを用いて、どのように分散型IDの仕組みが機能するかを具体的に解説します。
まずユーザーは自身の個人情報を管理するために、アプリケーションを使って上記のようなDIDを作成し、さらにDID Documentをブロックチェーンに書き込みます。
続いて、ユーザーは検証可能な個人情報(VCs)を情報提供機関から発行してもらい、自身のDIDに関連付けてもらうことでDIDの中身を構築していきます。
たとえば、自分が卒業した学校の情報(=検証可能な情報)を、卒業した学校(=情報提供機関)によって関連付けてもらうことで、DID Documentに自身の卒業校の情報が書き込まれます。
企業への入社時に卒業した学校の情報を提供する必要があれば、上記のDIDを企業に開示するだけで情報の提供は完了します。
企業は提供されたDIDのリンクからこのユーザーのDID Documentを閲覧することで、ユーザーが卒業した学校名を確認することができます。
また、DIDは必要に応じて関連付ける情報の内容を変えて構築することができます。
上記のように企業への入社時には、自身の学生時代に関する情報のうち企業から提出を求められているものを1つのDIDにまとめて提出することができます。また、銀行から融資を受ける際には、自身の信用に関する情報をまとめたDIDを別途作り、融資を受ける銀行に提出することができます。
そして、これらの情報はユーザー個人のストレージで保存することができるため、企業等の管理者によって恣意的に削除されたり、改ざんされることがありません。
Verifiable Credentials(検証可能な個人情報)
Verifiable Credentials(VCs)は検証可能な個人情報です。
先ほどの例においてユーザーが学校を卒業したという事実や、融資を受けられるだけの信用があるという事実は、情報提供機関がVCsをユーザーのDIDに付与することで、デジタル上でも確たる事実として扱われます。
仮に情報提供機関が倒産するなどして存在しなくなった場合も、一度DIDに付与された情報はブロックチェーン上に残るため、自身のことを証明する情報としてユーザーは保存・管理・利用することができます。
Self Sovereign Identity(自己主権型アイデンティティ)

分散型IDの仕組みの根底にあるのがSelf Sovereign Identity(SSI)という概念です。
SSIとは「特定の管理主体を必要とせず、自分自身が自らのデジタルなアイデンティティを保有・管理し、自身の存在を証明する」ことを目指す考え方です。
現実の世界では、わたしたちは運転免許証やパスポートを用いることで、自分が何者であるか(=アイデンティティ)を誰に対しても証明することができます。
ところが、デジタルの世界では自分の存在を証明してくれる確たる証拠がありません。
その証拠がないからこそ、わたしたちは何らかのサービスを利用する際には、自分が何者かを逐一伝え、アカウントを作ることで自己を証明するしかありません。
一方で、デジタルの世界でも現実世界と同じように自分であることを証明できるとする考え方がSSIです。
DIDやVCsといった仕組みを用いることで、管理者に依存することなく個人が主権を持って自分自身を証明することができます。
なぜ分散型IDが注目されるのか

昨今はWeb3という言葉が一人歩きしている感もありますが、分散型ID自体は中央集権的なデータ管理の仕組みに対抗する概念として以前から議論されています。
ここまでの解説を踏まえて、分散型IDが注目を集める理由を改めて整理します。
中央集権的な個人情報管理からの脱却
分散型IDが求められる最も大きな理由は、中央集権的な個人情報の管理体制からの脱却です。
すでに述べた通り、特定の管理者に情報を握られていることで以下の弊害が起こります。
- 膨大なアカウントの管理
- 企業の一存によるアカウントの停止
- 情報漏洩のリスク
つまり、わたしたち個人はデジタル世界において自分自身の情報をコントロールできず、すべてを企業等の管理者に委ねてしまっていることになります。
この状況を脱却するために注目を集めている技術・概念が分散型IDです。
分散型IDを用いることで、
- 個々の企業に対してアカウントを作成する必要がなくなる
- 他者の手で勝手にサービス利用を停止されたり、データを消されることがない
- 情報自体は渡す必要がないので、漏洩が起きない
というように、中央集権的な情報管理の弊害を解決することが期待されています。
個人情報を保有することによる企業側のリスク減少
現在の仕組みでは情報を持つ側として強い立場にある企業ですが、企業にとっても現行の中央集権的な仕組みはリスクがあります。
特に情報漏洩の問題は重要です。
ユーザー視点で見た「個人情報が勝手に流出する」リスク以上に、企業視点で見た「顧客の情報を流出させてしまう」リスクの方が、社会的な責任も含めて考えるとより重いものであるとも言えます。
個人情報を安全に保管するにはコストもかかるため、できることなら個人情報を持ちたくないという考えは企業側にもあります。
分散型IDの導入は、収集した顧客情報を活用したマーケティング・販売ができなくなるという点において企業にとって痛手ですが、個人情報の漏洩リスクを回避し、情報管理のコストも削減できる点においてはメリットがあるとも言えます。
分散型IDの課題
既存の情報管理の仕組みを根本的に解決し得る分散型IDですが、課題もあります。
それは「ユーザーは中央集権的な情報管理に慣れすぎてしまっている」ことです。
企業による個人情報の流出が起こる度に、企業の情報管理に対する世間の目は厳しくなっています。
しかし「個人情報の管理を中央集権的な管理者から自分たちの手に取り戻す」という動機だけで、これまで企業が提供してきた利便性の高いサービスを放棄できる人は、そう多くないはずです。
暗号資産ウォレットさえ使いこなせる人は多くない中、Google、Amazon、Appleなどの便利なサービスからわざわざ使いにくい分散型のサービスに人々が乗り換えるには、まだまだ時間がかかるはずです。
ユーザーインターフェースの改善はもちろんのこと、分散型IDに乗り換えるだけのインセンティブを設計できるかどうかが、今後の分散型IDの普及における課題だと言えます。
分散型IDの今後の展望まとめ
本記事では分散型IDの仕組みや、分散型IDが求められるようになった背景について解説しました。
企業による中央集権的なデータ管理のおかげでわたしたちは利便性の高いサービスを享受している一方、自身の個人情報に関する一切の主権を企業に渡してしまっているのが現在のインターネットの構図です。
膨大なアカウント管理の手間や、企業による恣意的なサービスの利用停止処置、あるいは情報漏洩のリスク等の課題を解決するために、分散型IDの普及が待たれます。
わたしたち一般ユーザーも分散型ID導入の必要性を理解し、実用化の際には使いこなせるように、今のうちから知識を蓄えていきましょう。


